Data Warehouse vs Data Mart vs Data Lake
Los términos lago de datos y almacén de datos se confunden a menudo y a veces se utilizan indistintamente. De hecho, aunque ambos se utilizan para almacenar conjuntos de datos masivos, los lagos de datos y los almacenes de datos son diferentes (y pueden ser complementarios).
- Lago de datos: es un conjunto masivo de datos que puede contener cualquier tipo de datos: estructurados, semiestructurados o no estructurados.
- Almacén de datos: es un depósito de datos estructurados y filtrados que ya han sido procesados para un fin específico. En otras palabras, un almacén de datos está bien organizado y contiene datos bien definidos.
- Data mart - es un subconjunto de un almacén de datos, utilizado por una unidad de negocio específica de la empresa para un propósito concreto, como una aplicación de gestión de la cadena de suministro.
James Dixon, creador del término lago de datos, explica las diferencias mediante una analogía: "Si pensamos en un mercado de datos como un almacén de agua embotellada -limpiada, envasada y estructurada para facilitar su consumo-, el lago de datos es una gran masa de agua en un estado más natural. El contenido del lago de datos fluye desde una fuente para llenarlo, y varios usuarios del lago pueden venir a examinarlo, sumergirse en él o tomar muestras".
Un lago de datos puede utilizarse junto con un almacén de datos. Por ejemplo, puede utilizar un lago de datos como un repositorio de aterrizaje y puesta en escena para un almacén de datos. Puede utilizar el lago de datos para curar o limpiar los datos antes de introducirlos en un almacén de datos u otras estructuras de datos.
Los lagos de datos que no se curan corren el riesgo de convertirse en pantanos de datos sin ninguna gobernanza o decisiones de calidad aplicadas a los datos, lo que disminuye radicalmente el valor de recopilar los datos al "embarrar" datos de calidad mixta de una manera que hace difícil confiar en la validez de las decisiones que se toman a partir de los datos recopilados.
El siguiente diagrama representa una pila tecnológica típica de lago de datos. El lago de datos incluye recursos de almacenamiento y computación escalables; herramientas de procesamiento de datos para gestionarlos; herramientas de análisis y elaboración de informes para científicos de datos, usuarios empresariales y personal técnico; y sistemas comunes de gobernanza, seguridad y operaciones de datos.
Puede implementar un lago de datos en el centro de datos de una empresa o en la nube. Muchos de los primeros en adoptarlos implementaron los lagos de datos in situ. A medida que los lagos de datos se vuelven más frecuentes, muchos de los principales adoptantes están buscando lagos de datos basados en la nube para acelerar el tiempo de creación de valor, reducir el coste total de propiedad y mejorar la agilidad empresarial.
Los lagos de datos locales consumen mucho CAPEX y OPEX
Se puede implementar un lago de datos en el centro de datos de una empresa utilizando servidores básicos y almacenamiento local (interno). En la actualidad, la mayoría de los lagos de datos locales utilizan como plataforma de datos una versión comercial o de código abierto de Hadoop, un popular marco informático de alto rendimiento. (En la encuesta de TDWI, el 53% de los encuestados utiliza Hadoop como plataforma de datos, mientras que sólo el 6% utiliza un sistema de gestión de bases de datos relacionales).
Puede combinar cientos o miles de servidores para crear un clúster Hadoop escalable y resistente, capaz de almacenar y procesar conjuntos de datos masivos. El siguiente diagrama muestra una pila tecnológica para un lago de datos local en Apache Hadoop.
La pila tecnológica incluye:
-
Hadoop MapReduce:
Un marco de software para escribir fácilmente aplicaciones que procesan grandes cantidades de datos en paralelo en grandes clústeres de hardware básico de forma fiable y tolerante a fallos.
-
Hadoop YARN:
Un marco para la programación de trabajos y la gestión de recursos de clúster.
-
Sistema de archivos distribuidos Hadoop (HDFS):
Un sistema de archivos de alto rendimiento diseñado específicamente para ejecutarse en servidores de bajo coste, con unidades de disco internas económicas.
Los lagos de datos locales ofrecen un alto rendimiento y una gran seguridad, pero son muy caros y complicados de implantar, administrar, mantener y ampliar. Entre las desventajas de un lago de datos local se incluyen:
Instalación prolongada
Construir su propio lago de datos requiere mucho tiempo, esfuerzo y dinero. Hay que diseñar y crear el sistema; definir e implantar sistemas y buenas prácticas de seguridad y administración; adquirir, poner en marcha y probar la infraestructura informática, de almacenamiento y de redes; e identificar, instalar y configurar todos los componentes de software. Normalmente se tardan meses (a menudo más de un año) en poner en marcha un lago de datos on-prem.
Alto CAPEX
Los importantes desembolsos iniciales en equipos conducen a modelos de negocio desequilibrados con escasa rentabilidad y largos plazos de amortización. Los servidores, los discos y la infraestructura de red están sobredimensionados para satisfacer los picos de demanda de tráfico y los requisitos de capacidad futuros, por lo que siempre se está pagando por recursos informáticos ociosos y capacidad de almacenamiento y red no utilizada.
Alto OPEX
Los gastos recurrentes de energía, refrigeración y espacio en bastidores; las cuotas mensuales de mantenimiento de hardware y soporte de software; y los costes continuos de administración de hardware se traducen en elevados gastos de explotación de los equipos.
Alto riesgo
Garantizar la continuidad de la actividad (replicar los datos en tiempo real en un centro de datos secundario) es una propuesta cara que está fuera del alcance de la mayoría de las empresas. Muchas empresas realizan copias de seguridad en cinta o disco. En caso de catástrofe, reconstruir los sistemas y restablecer las operaciones puede llevar días o incluso semanas.
Administración de sistemas complejos
La gestión de un lago de datos in situ exige muchos recursos, lo que desvía al valioso (y caro) personal de TI de tareas más estratégicas.
Los lagos de datos en la nube eliminan el coste y la complejidad de los equipos
Puede implantar un lago de datos en una nube pública para evitar gastos en equipos y molestias y acelerar las iniciativas de big data. Las ventajas generales de un lago de datos basado en la nube incluyen:
Rápida amortización
Puede reducir el tiempo de implantación de meses a semanas eliminando los esfuerzos de diseño de la infraestructura y las tareas de adquisición, instalación y puesta en marcha del hardware.
No CAPEX
Puede evitar desembolsos iniciales de capital, ajustar mejor los gastos a las necesidades de la empresa y liberar presupuesto de capital para otros programas.
Sin gastos de funcionamiento de los equipos
Puede eliminar los gastos continuos de funcionamiento de los equipos (energía, refrigeración, inmuebles), las cuotas anuales de mantenimiento del hardware y los costes recurrentes de administración del sistema.
Escalabilidad instantánea e infinita
Puede añadir capacidad informática y de almacenamiento bajo demanda para satisfacer los requisitos empresariales en rápida evolución y mejorar la satisfacción del cliente (responder rápidamente a los requisitos de la línea de negocio).
Escala independiente
A diferencia de una implementación de Hadoop en las instalaciones, que depende de servidores con almacenamiento interno, con una implementación en la nube se puede escalar la capacidad de computación y almacenamiento de forma independiente para optimizar los costes y aprovechar al máximo los recursos.
Menor riesgo
Puede replicar datos entre regiones para mejorar la capacidad de recuperación y garantizar la disponibilidad continua en caso de catástrofe.
Operaciones simplificadas
Puede liberar al personal informático para que se centre en tareas estratégicas de apoyo a la empresa (el proveedor de la nube gestiona la infraestructura física).
Los servicios de almacenamiento en nube de primera generación son demasiado costosos y complejos para los lagos de datos
En comparación con un lago de datos local, un lago de datos basado en la nube es mucho más fácil y menos costoso de implementar, escalar y operar. Dicho esto, los servicios de almacenamiento de objetos en la nube de primera generación, como AWS S3, Microsoft Azure Blob Storage y Google Cloud Platform Storage, son intrínsecamente costosos (en muchos casos tan caros como las soluciones de almacenamiento locales) y complicados. Muchas empresas buscan servicios de almacenamiento más sencillos y asequibles para sus iniciativas de lago de datos. Entre las limitaciones de los servicios de almacenamiento de objetos en la nube de primera generación se incluyen:
Niveles de servicio caros y confusos
Los proveedores de nubes heredadas venden varios tipos diferentes (niveles) de servicios de almacenamiento. Cada nivel se destina a un fin distinto, por ejemplo, almacenamiento primario para datos activos, almacenamiento de archivo activo para recuperación ante desastres o almacenamiento de archivo inactivo para conservación de datos a largo plazo. Cada uno tiene características únicas de rendimiento y resistencia, acuerdos de nivel de servicio y planes de precios. Las complicadas estructuras de tarifas con múltiples variables de precios dificultan la toma de decisiones informadas, la previsión de costes y la gestión de presupuestos.
Fijación del proveedor
Cada proveedor de servicios admite una API única. Cambiar de servicio es una propuesta cara y lenta: hay que reescribir o cambiar las herramientas y aplicaciones de gestión del almacenamiento existentes. Peor aún, los proveedores heredados cobran tarifas excesivas de transferencia de datos (salida) para mover datos fuera de sus nubes, lo que hace que sea caro cambiar de proveedor o aprovechar una combinación de proveedores.
Cuidado con los servicios de almacenamiento por niveles
Los proveedores de almacenamiento en la nube de primera generación ofrecen confusos servicios de almacenamiento por niveles. Cada nivel de almacenamiento está destinado a un tipo específico de datos y tiene características de rendimiento, acuerdos de nivel de servicio y planes de precios distintos (con estructuras de tarifas complejas).
Aunque la cartera de cada proveedor es ligeramente diferente, estos servicios escalonados suelen estar optimizados para tres clases distintas de datos.
Datos activos
Datos activos a los que el sistema operativo, una aplicación o los usuarios pueden acceder fácilmente. A los datos activos se accede con frecuencia y tienen estrictos requisitos de rendimiento de lectura/escritura.
Archivo activo
Datos a los que se accede ocasionalmente y que están disponibles en línea al instante (no se restauran y rehacen desde una fuente remota o sin conexión). Algunos ejemplos son las copias de seguridad para una rápida recuperación en caso de catástrofe o los archivos de vídeo de gran tamaño a los que se puede acceder de vez en cuando con poca antelación.
Archivo inactivo
Datos a los que se accede con poca frecuencia. Por ejemplo, los datos que se mantienen a largo plazo para cumplir la normativa. Históricamente, los datos inactivos se archivan en cinta y se almacenan fuera de las instalaciones.
Identificar la mejor clase de almacenamiento (y el mejor valor) para una aplicación concreta puede ser un verdadero reto con un proveedor de almacenamiento en la nube heredado. Microsoft Azure, por ejemplo, ofrece cuatro opciones distintas de almacenamiento de objetos: General Purpose v1, General Purpose v2, Blob Storage y Premium Blob Storage. Cada opción tiene características únicas de precio y rendimiento. Y algunas de las opciones (aunque no todas) admiten tres niveles de almacenamiento distintos, con acuerdos de nivel de servicio y tarifas diferentes: almacenamiento en caliente (para datos a los que se accede con frecuencia), almacenamiento en frío (para datos a los que se accede con poca frecuencia) y almacenamiento de archivo (para datos a los que se accede con poca frecuencia). Con tantas opciones y variables de precios, es casi imposible tomar una decisión bien informada y presupuestar los gastos con precisión.
En IDrive® e2, creemos que el almacenamiento en la nube debe ser sencillo. A diferencia de los servicios de almacenamiento en la nube heredados con niveles de almacenamiento confusos y esquemas de precios enrevesados, ofrecemos un único producto, con precios predecibles, asequibles y sencillos, que satisface cualquier necesidad de almacenamiento en la nube. Puede utilizar IDrive® e2 para cualquier clase de almacenamiento de datos: datos activos, archivo activo y archivo inactivo.
IDrive® e2 Hot Cloud Storage para lagos de datos
IDrive® e2 hot cloud storage es un almacenamiento de objetos en la nube extremadamente económico, rápido y fiable para cualquier propósito. A diferencia de los servicios de almacenamiento en la nube de primera generación con confusos niveles de almacenamiento y complejos esquemas de precios, IDrive® e2 es fácil de entender y extremadamente rentable a escala. IDrive® e2 es ideal para almacenar volúmenes masivos de datos en bruto.
Entre las principales ventajas de IDrive® e2 para los lagos de datos se incluyen:
Precios de las materias primas
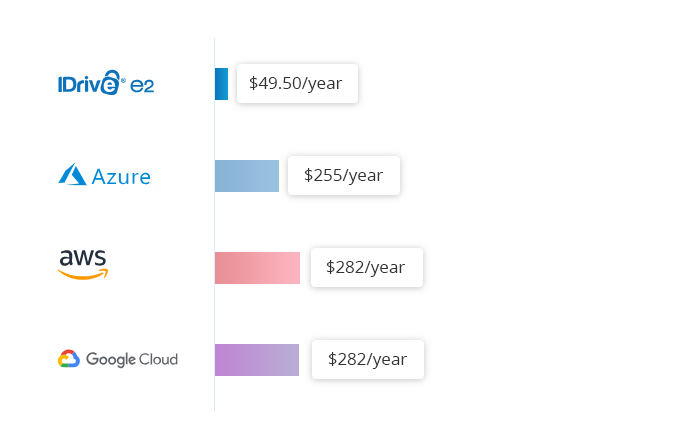
El almacenamiento en nube en caliente IDrive® e2 cuesta 0,004 $/GB/mes. Compárelo con los 0,023 $/GB/mes de Amazon S3 Standard, los 0,026 $/GB/mes de Google Multi-Regional y los 0,046 $/GB/mes de Azure RA-GRS Hot.
A diferencia de AWS, Microsoft Azure y Google Cloud Platform, no imponemos tarifas adicionales para recuperar datos del almacenamiento (tarifas de salida). Tampoco cobramos tarifas adicionales por las llamadas a la API.
Rendimiento superior
La arquitectura paralela del sistema IDrive® e2 ofrece un rendimiento de lectura/escritura superior al de los servicios de almacenamiento en la nube de primera generación, con velocidades de tiempo hasta el primer byte significativamente más rápidas.
Durabilidad y protección sólidas de los datos
El almacenamiento en caliente en la nube IDrive® e2 está diseñado para ofrecer una durabilidad, integridad y seguridad extremas de los datos. Una capacidad opcional de inmutabilidad de datos evita eliminaciones accidentales y contratiempos administrativos; protege contra malware, errores y virus; y mejora el cumplimiento normativo.
IDrive® e2 Hot Cloud Storage para Apache Hadoop Data Lakes
Si ejecuta su lago de datos en Apache Hadoop, puede utilizar el almacenamiento en caliente en la nube IDrive® e2 como alternativa asequible a HDFS, como se muestra en el diagrama siguiente. El almacenamiento en caliente en la nube IDrive® e2 es totalmente compatible con la API S3 de AWS. Puede utilizar el conector Hadoop Amazon S3A, que forma parte de la distribución Apache Hadoop de código abierto, para integrar Amazon S3 y otro almacenamiento en la nube compatible como IDrive® e2 en varios flujos MapReduce.
Puede utilizar el almacenamiento en nube en caliente IDrive® e2 como parte de la implementación de un lago de datos multicloud para mejorar las opciones y evitar la dependencia de un proveedor. Un enfoque multicloud le permite escalar los recursos informáticos y de almacenamiento del lago de datos de forma independiente, utilizando los mejores proveedores.
También puede conectar su nube privada directamente a IDrive® e2. A diferencia de lo que ocurre con los proveedores de almacenamiento en la nube de primera generación, con IDrive® e2 nunca pagará tasas de transferencia (salida) de datos. En otras palabras, puede mover datos libremente fuera de IDrive® e2.
Continuidad de negocio y recuperación tras catástrofes económicas
IDrive® e2 está alojado en múltiples centros de datos distribuidos geográficamente para una mayor resistencia y disponibilidad. Puede replicar datos a través de las regiones de IDrive® e2 para la continuidad del negocio, recuperación de desastres y protección de datos, como se muestra a continuación.
Por ejemplo, podría replicar datos en tres centros de datos IDrive® e2 diferentes (regiones) utilizando:
- IDrive® e2 Data Center 1 para el almacenamiento activo de datos (almacenamiento primario).
- IDrive® e2 Data Center 2 como archivo activo para copias de seguridad y recuperación (hot standby en caso de que el Data Center 1 sea inaccesible).
- IDrive® e2 Data Center 3 como un almacén de datos inmutable (para proteger los datos contra contratiempos administrativos, borrados accidentales y ransomware). Un objeto de datos inmutable no puede ser borrado ni modificado por nadie, ni siquiera por IDrive® e2.